来自:网络,侵删
-
从最简单的开始:万事合一。 -
可扩展性的艺术:纵向扩展,横向扩展。 -
扩展关系型数据库:主 – 从复制、主 – 主复制、联合、分片、非规范化和 SQL 调优。 -
使用哪种数据库:NoSQL 还是 SQL? -
先进概念:缓存、CDN、geoDNS 等。
1. 从头开始
-
一个网站(包括 API)在 Apache(或 Tomcat)等网络服务器上运行。 -
一个 Oracle(或 MySQL)之类的数据库。

-
如果数据库出现故障,则系统将失效。 -
一旦网络服务器出现故障,则会导致整个系统的瘫痪。
使用 DNS 服务器来解析主机名和 IP 地址
每次访问网站时,计算机都会执行 DNS 查询。
2. 可扩展性的艺术
可扩展性一般是指添加更多的资源,在不影响用户体验的情况下处理更多的用户、客户机、数据、事务或请求。
纵向扩展(scale up) 和横向扩展(scale out)。
纵向扩展:在现有服务器上增加更多的内存和 CPU
如果我们运行的服务器有 8G 的内存,那么只要更换或者增加硬件,就可以轻松地提升到 32G,甚至 128G。
-
通过在 RAID 阵列中增加更多的硬盘来增加 I/O 容量。 -
通过切换到固态硬盘(SSD)来改善 I/O 访问时间。 -
切换到具有更多处理器的服务器。 -
通过升级网络接口或安装额外的网络接口来提高网络吞吐量。 -
通过增加内存来减少 I/O 操作。
-
“不可能在一台服务器上增加无限的能力”。这主要取决于操作系统和服务器的内存总线宽度。 -
给系统升级内存时,必须关掉服务器,因此,如果系统只有一台服务器,停机是不可避免的。 -
强大的机器往往要比流行的硬件昂贵很多。
相比之下,纵向减缩(scale down)是指从现有的服务器中移除现有的资源,如 CPU、内存和磁盘。
您需要多台服务器吗?

-
可对 Web 服务器进行不同于数据库服务器的调优。 -
网络服务器需要更好的 CPU,而数据库服务器需要更多的内存。 -
为 Web 层和数据层提供单独的服务器,允许它们彼此独立地进行扩展。
横向扩展:添加任意数量的硬件和软件实体
与此相反,横向减缩(Scale in)指的是删除现有服务器的过程。
3. 使用负载均衡器来均衡所有节点上的流量

HAProxy 和 Nginx 是目前比较受欢迎的开源负载均衡软件。
-
如果服务器 1 脱机,则所有的流量将被路由到服务器 2 和服务器 3。网站就不会脱机。你还需要在服务器池中添加一个新的健康服务器来均衡负载。 -
当流量快速增长时,你只需要向网站服务器池添加更多的服务器,负载均衡器将为你路由流量。
-
循环:在这种情况下,每个服务器按顺序接收请求,类似于先进先出(FIFO)。 -
最少的连接数:连接数最少的服务器将被引导到请求。 -
最快的响应时间:具有最快响应时间的服务器(最近或经常)将被引导到请求。 -
加权:较强大的服务器将比较弱的服务器收到更多的请求加权策略。 -
IP 哈希:在这种情况下,计算客户的 IP 地址的哈希值,将请求重定向到服务器。
-
从共享 IP 中添加和删除真正的服务器,将会立即发生。 -
负载均衡可以根据需要进行。
-
第 4 层:负载均衡器使用网络层的 TCP 提供的信息。在这一层,它一般不会查看所请求的内容,而是选择一台服务器。 -
第 7 层:请求可以根据查询字符串、cookies 或我们选择的任何头的信息,以及包括源和目标地址在内的常规层信息进行均衡。
4. 扩展关系数据库
-
复制 通常指的是一种技术,可以让我们在不同的机器上存储同一数据的多个副本。 -
联合(或功能分区)将数据库按功能进行划分。 -
分片 是一种与分区相关的数据库架构模式,它将数据的不同部分放到不同的服务器上,不同的用户将访问数据集的不同部分。 -
非规范化 试图以牺牲一些写入性能为代价来提高读取性能,将数据写入多个表中以避免昂贵的连接。 -
SQL 调优。
主 – 从复制

-
客户端将连接到主服务器,并更新数据。 -
数据随后会在从服务器上进行传输,直到所有的数据在服务器上都是一致的。
-
如果主服务器由于某种原因宕机了,数据仍然可以通过从服务器获得,但是将无法再进行新的写入。 -
我们还需要一种新的算法,把一台从服务器提升到主服务器。
-
同步解决方案:只有当所有的服务器都接受了修改数据的事务(分布式事务)之后,才会被提交,因此,当发生故障切换时,数据不会丢失。 -
异步解决方案:提交 → 延迟 → 传播到集群中的其他服务器,因此,当发生故障切换时,某些数据更新会丢失。
主 – 主复制

-
当一台主服务器发生故障时,其他数据库服务器可以正常运行,并接替其工作。当数据库服务器重新上线时,它将利用复制的方式赶上来。 -
主服务器可以位于几个物理站点,也可以分布在网络上。 -
受限于主服务器处理更新的能力。
联合

分片
-
每个用户只需要和一个服务器对话,所以可以从该服务器得到快速的响应。 -
负载在服务器之间得到了很好的均衡——例如,如果我们有五个服务器,每个服务器只需要处理 20% 的负载。
水平分区

垂直分区
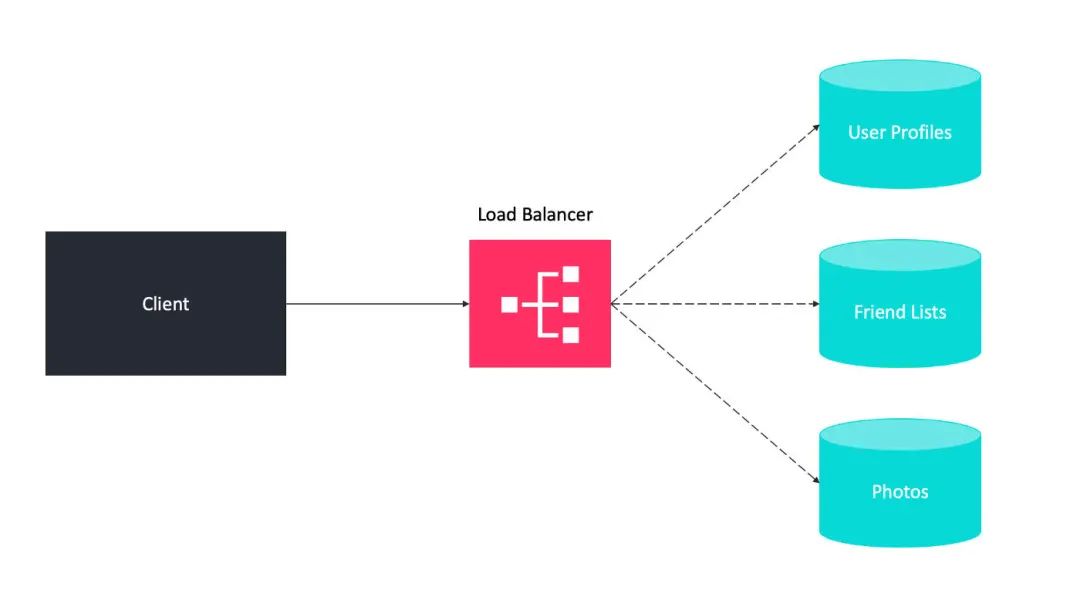
基于目录的分区
-
数据库连接变得更加昂贵,在某些情况下是不可行的。 -
分片会破坏数据库的引用完整性。 -
数据库模式的改变会变得非常昂贵。 -
数据分布不均匀,而且在分片上有大量负载。
非规范化
5. 使用哪个数据库?
SQL
NoSQL
键值存储
key(键)是一个与 value(值)相连的属性名称。文档数据库
宽列式数据库
图数据库
Blob 数据库
当涉及数据库技术时,没有放之四海而皆准的解决方案。这就是为什么许多企业同时依赖 SQL 和 NoSQL 数据库来满足不同的需求。

6. 横向扩展 Web 层

7. 先进概念
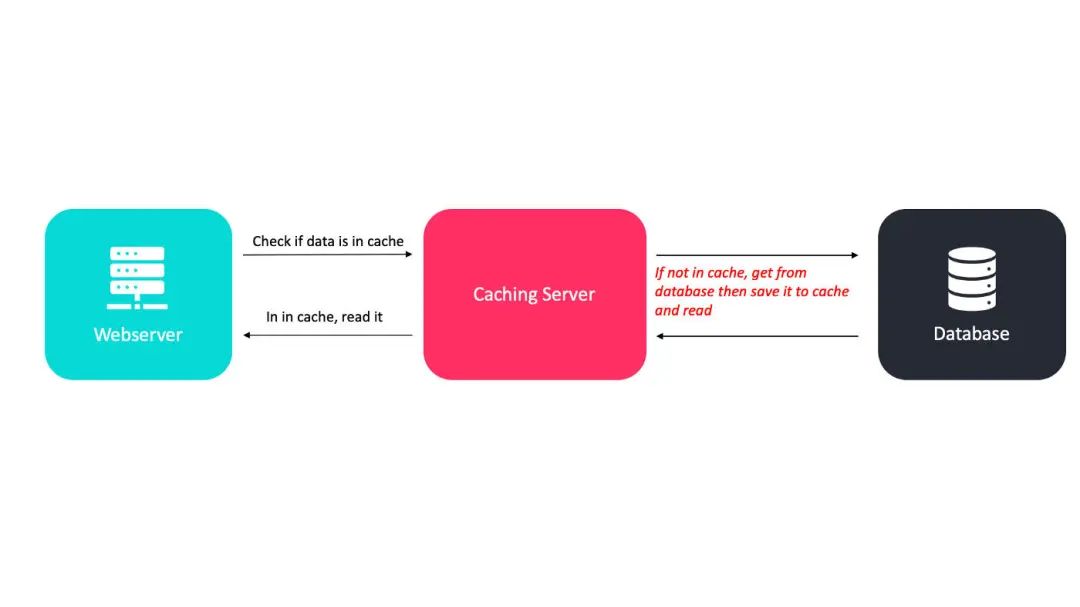
缓存
内容分发网络 (CDN )
走向全球

把它整合在一起

8. 后面会讨论哪些话题?
-
分片和复制技术相结合。 -
长轮询 vs Websockets vs 服务器发送事件。 -
索引和代理。 -
SQL 调优。 -
弹性计算。
阅读全文
下载说明:
1、本站所有资源均从互联网上收集整理而来,仅供学习交流之用,因此不包含技术服务请大家谅解!
2、本站不提供任何实质性的付费和支付资源,所有需要积分下载的资源均为网站运营赞助费用或者线下劳务费用!
3、本站所有资源仅用于学习及研究使用,您必须在下载后的24小时内删除所下载资源,切勿用于商业用途,否则由此引发的法律纠纷及连带责任本站和发布者概不承担!
4、本站站内提供的所有可下载资源,本站保证未做任何负面改动(不包含修复bug和完善功能等正面优化或二次开发),但本站不保证资源的准确性、安全性和完整性,用户下载后自行斟酌,我们以交流学习为目的,并不是所有的源码都100%无错或无bug!如有链接无法下载、失效或广告,请联系客服处理!
5、本站资源除标明原创外均来自网络整理,版权归原作者或本站特约原创作者所有,如侵犯到您的合法权益,请立即告知本站,本站将及时予与删除并致以最深的歉意!
6、如果您也有好的资源或教程,您可以投稿发布,成功分享后有站币奖励和额外收入!
7、如果您喜欢该资源,请支持官方正版资源,以得到更好的正版服务!
8、请您认真阅读上述内容,注册本站用户或下载本站资源即您同意上述内容!
原文链接:https://www.shuli.cc/?p=19909,转载请注明出处。
1、本站所有资源均从互联网上收集整理而来,仅供学习交流之用,因此不包含技术服务请大家谅解!
2、本站不提供任何实质性的付费和支付资源,所有需要积分下载的资源均为网站运营赞助费用或者线下劳务费用!
3、本站所有资源仅用于学习及研究使用,您必须在下载后的24小时内删除所下载资源,切勿用于商业用途,否则由此引发的法律纠纷及连带责任本站和发布者概不承担!
4、本站站内提供的所有可下载资源,本站保证未做任何负面改动(不包含修复bug和完善功能等正面优化或二次开发),但本站不保证资源的准确性、安全性和完整性,用户下载后自行斟酌,我们以交流学习为目的,并不是所有的源码都100%无错或无bug!如有链接无法下载、失效或广告,请联系客服处理!
5、本站资源除标明原创外均来自网络整理,版权归原作者或本站特约原创作者所有,如侵犯到您的合法权益,请立即告知本站,本站将及时予与删除并致以最深的歉意!
6、如果您也有好的资源或教程,您可以投稿发布,成功分享后有站币奖励和额外收入!
7、如果您喜欢该资源,请支持官方正版资源,以得到更好的正版服务!
8、请您认真阅读上述内容,注册本站用户或下载本站资源即您同意上述内容!
原文链接:https://www.shuli.cc/?p=19909,转载请注明出处。

评论0